System.Xml.XPath命名空间是建立在速度的基础上的,它提供了XML文档的一种只读视图,但没有编辑功能。这个命名空间中的类XPath可以采用光标的方式在XML文档上进行快速迭代和选择操作。
表23-7列出了System.Xml.XPath命名空间中的重要类,并对每个类的功能进行了简单的说明。
表 23-7
|
类 名 |
说 明 |
|
XpathDocument |
提供整个XML文档的视图,只读 |
|
XpathNavigator |
提供XPathDocument的浏览功能 |
|
XpathNodeIterator |
提供节点集的迭代功能,XPath等价于XPath中的节点集 |
|
XpathExpression |
编译好的XPath表达式,由SelectNodes、SelectSingleNodes、Evaluate 和 Matches使用 |
|
XpathException |
XPath异常类 |
XPathDocument没有提供XmlDocument类的任何功能,如果需要编辑功能,就应选择XmlDocument,如果要使用ADO.NET,就应选择XmlDataDocument(见本章后面的内容),如果速度比较重要,就应使用XPathDocument。它有4个重载方法,可以从文件和路径字符串、TextReader对象、XmlReader对象或基于Stream的对象中打开XML文档。
XPathNavigator包含所需移动和选择元素的所有方法,其中的一些移动方法如表23-8所示。
表 23-8
|
方 法 名 |
说 明 |
|
MoveTo() |
把XPathNavigator作为参数,移动当前位置到XPathNavigator指定的地方 |
|
MoveToAttribute() |
移动到指定的属性,其参数是属性名和命名空间 |
|
MoveToFirstAttribute() |
移动到当前元素中的第一个属性上,如果成功,就返回true |
|
MoveToNextAttribute() |
移动到当前元素中的下一个属性上,如果成功,就返回true |
|
MoveToFirst() |
移动到当前节点中的第一个同级节点上,如果成功,就返回true。否则返回false |
|
MoveToLast() |
移动到当前节点中的最后一个同级节点上,如果成功,就返回true |
|
MoveToNext() |
移动到当前节点中的下一个同级节点上,如果成功,就返回true |
|
MoveToPrevious() |
移动到当前节点中的上一个同级节点上,如果成功,就返回true |
|
MoveToFirstChild() |
移动到当前元素中的第一个子元素上,如果成功,就返回true |
|
MoveToId() |
移动到ID参数提供的元素上,文档中需要有一个模式,元素的数据类型必须是ID类型 |
|
MoveToParent() |
移动到当前节点的父节点上,如果成功,就返回true |
|
MoveToRoot() |
移动到文档的根节点上 |
有几个Select()方法可以选择出要操作的节点子集。所有的Select方法都返回一个XPathNodeIterator对象。
还可以使用SelectAncestors() 和 SelectChildren()方法。它们都返回一个XpathNodeIterator对象。Select的参数是一个XPath表达式,其他选择方法的参数是一个XPathNodeType。
可以扩展XpathNavigator,使用文件系统或注册表作为存储器,来代替XpathDocument。
XPathNodeIterator可以看作是XPath中的NodeList 或NodeSet,这个对象有3个属性和两个方法:
● Clone—— 创建它本身的一个新副本。
● Count—— XPathNodeIterator对象中的节点数。
● Current—— 返回指向当前节点的XPathNavigator。
● CurrentPosition()—— 返回表示当前位置的一个整数。
● MoveNext()—— 移动到匹配XPath表达式的下一个节点上,创建XPathNodeIterator。
要理解这些类的用法,最好是查看一下迭代books.xml文档的代码,确定导航是如何工作的。为了使用这些示例,首先需要添加对System.Xml.Xsl 和 System.Xml.XPath命名空间的引用,如下所示:
using System.Xml.XPath;
using System.Xml.Xsl;
这个示例使用了文件booksxpath.xml,它类似于前面使用的books.xml,但booksxpath.xml添加了两本书。下面是窗体代码,这段代码在XPathXSLSample1文件夹中:
private void button1_Click(object sender, System.EventArgs e)
{
//modify to match your path structure
XPathDocument doc=new XPathDocument("..\\..\\..\\booksxpath.xml");
//create the XPath navigator
XPathNavigator nav=doc.CreateNavigator();
//create the XPathNodeIterator of book nodes
// that have genre attribute value of novel
XPathNodeIterator iter=nav.Select("/bookstore/book[@genre='novel']");
while(iter.MoveNext())
{
LoadBook(iter.Current);
}
}
private void LoadBook(XPathNavigator lstNav)
{
//We are passed an XPathNavigator of a particular book node
//we will select all of the descendents and
//load the list box with the names and values
XPathNodeIterator iterBook=lstNav.SelectDescendants
(XPathNodeType.Element, false);
while(iterBook.MoveNext())
listBox1.Items.Add(iterBook.Current.Name + ": "
+ iterBook.Current.Value);
}
在button1_Click()方法中,首先创建XPathDocument(叫做doc),其参数是要打开的文档的文件和路径字符串。下面一行代码创建XPathNavigator:
XPathNavigator nav = doc.CreateNavigator();
本例用Select方法获取genre属性值为novel的所有节点,然后使用MoveNext()方法迭代书籍列表中的所有小说。
要把数据加载到列表框中,使用XPathNodeIterator.Current属性,根据XPathNodeIterator指向的节点,创建一个新的XPathNavigator对象。在本例中,为文档中的一个book节点创建一个XPathNavigator。
LoadBook()方法提取这个XPathNavigator,调用Select方法的另一个重载方法SelectDescendants创建另一个XPathNavigator,这样,XPathNodeIterator就包含了给LoadBook方法发送的book节点的所有子节点。
然后,在这个XPathNodeIterator上执行另一个MoveNext()循环,给列表框加载元素名称和元素值。在执行代码后,显示23-7所示的屏幕图,注意只列出了小说。
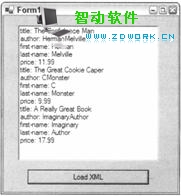
图 23-7
如果要把这些书的成本相加,该怎么办?XPathNavigator为此包含了Evaluate方法。Evaluate有3个重载方法,第一个包含一个字符串,该字符串就是XPath函数调用。第二个Evaluate重载方法的参数是XPathExpression对象,第三个Evaluate重载方法的参数是XPathExpression 和 XPathNodeIterator。如果对示例进行下述修改(这个版本的代码在XPathXSLSample2中):
private void button1_Click(object sender, System.EventArgs e)
{
//modify to match your path structure
XPathDocument doc = new XPathDocument("..\\..\\..\\booksxpath.XML");
//create the XPath navigator
XPathNavigator nav = doc.CreateNavigator();
//create the XPathNodeIterator of book nodes
// that have genre attribute value of novel
XPathNodeIterator iter = nav.Select("/bookstore/book[@genre='novel']");
while(iter.MoveNext())
{
LoadBook(iter.Current.Clone());
}
//add a break line and calculate the sum
listBox1.Items.Add("========================");
listBox1.Items.Add("Total Cost = "
+ nav.Evaluate("sum(/bookstore/book[@genre='novel']/price)"));
}
这次,可以看到列表框中书籍的总成本,如图23-8所示。

图 23-8
更多DotNet好文章www.zdexe.com